
La tecnología avanza y cuando te dedicas a ella no te queda otra que, “renovarte o morir”.
El mundo del Data Science me parece, a la vez, fascinante y muy complejo. En mi aprendizaje hay veces que me encuentro con conceptos totalmente nuevos y que requieren de un esfuerzo extra para comprender su utilidad. Me imagino que esto me ocurre, por la falta de una base solida de conocimientos, sobre todo en lo que se refiere a Estadística.
La semana pasada, jugueteando un poco con Azure ML, pude aprender una funcionalidad nueva y desde mi punto de vista, muy útil.
El escenario es el siguiente: Contamos con un dataset que contiene una gran cantidad de características. Nos gustaría considerar únicamente, aquellas cuyo valor predictivo sea el mas alto, descartando así las características más irrelevantes. El subconjunto obtenido será utilizado para entrenar el modelo.
Para ilustrar el ejemplo usaremos uno de los datasets disponibles en Azure. Tras unas transformaciones previas, vemos que el dataset contiene 4 columnas ‘Categorical’, 18 numéricas y nuestra variable de respuesta (Label).
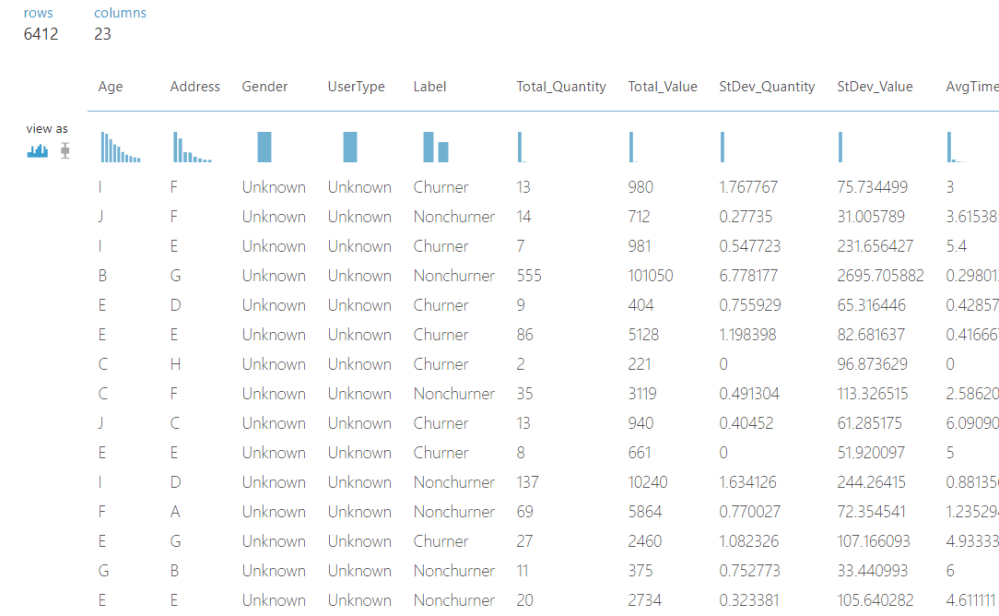
De las 22 características originales, escogeremos las 18 más significativas para la predicción de nuestra variable de respuesta.
Para ello, utilizaremos el modulo Feature Selection > Filter Based Feature Selection

Y lo configuraremos de la siguiente manera:
- Feature Scoring Method: Mutual Information
- Operate on feature columns only: seleccionado
- Target Column: Label (mi variable de respuesta)
- Number of desired features: 18

Este módulo creará un nuevo dataset con 18 características junto con nuestra columna objetivo ‘Label’. Cada característica será puntuada según sea su correlación con la columna objetivo ‘Label’ siguiendo el algoritmo de ‘Información Mutua’.
La información mutua de dos variables aleatorias es una cantidad que mide la dependencia mutua de las dos variables, es decir, mide la reducción de incertidumbre de una variable aleatoria X, debido al conocimiento del valor de otra variable aleatoria Y (Wikipedia)
Las características con las clasificaciones mas altas se mantienen
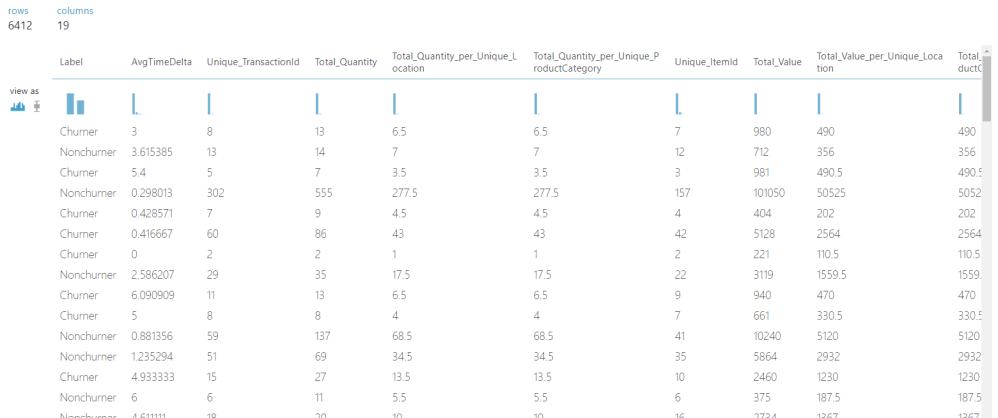
El dataset Features muestra la puntuación asociada a cada característica.

Resumiendo, mediante el uso del módulo Filter Based Feature Selection y siguiendo el algoritmo de ‘información mutua’, hemos podido seleccionar las 18 características que tienen mayor correlación con la columna objetivo ‘Label’, sobre un total de 22. Gracias a esto, el proceso de entrenamiento del modelo será más eficiente.
